A new NN/g study found four ways it falls short. Three are missing instructions. One is a problem no prompt can fix.
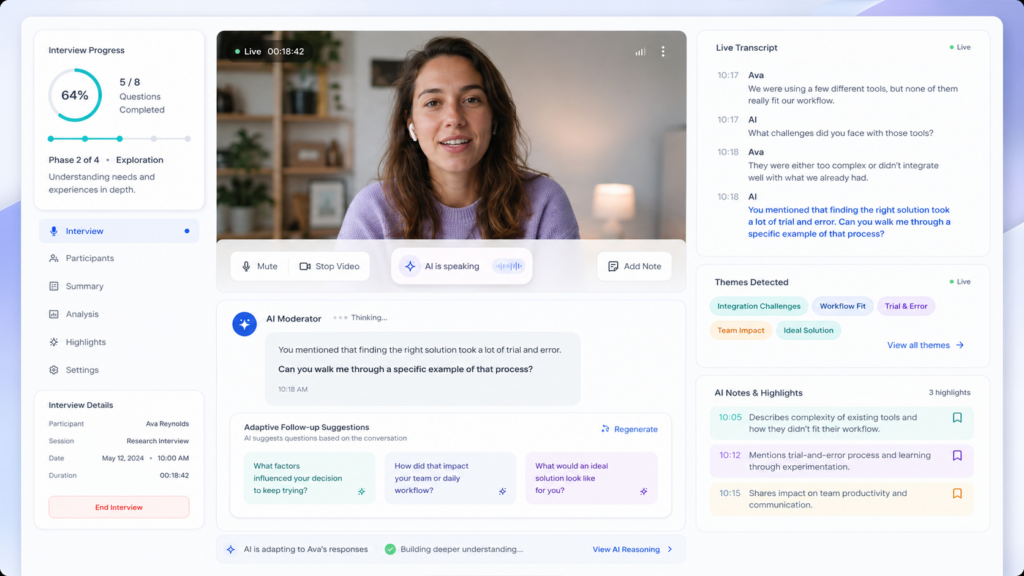
AI is starting to run interviews. Not transcribe them, not analyze them after the fact — run them. You hand it a research goal or an interview guide, and it asks the questions, listens to the answers, decides what to dig into, and follows up.
This should unsettle us a little before it excites us. An interview is one of the most personal things a person can engage in. You’re not just collecting information. You’re helping someone put their own story into words, and whether they say the true thing or the safe thing depends on whether they trust you. That trust gets built in small ways — a pause you leave open instead of filling, a follow-up that shows you were listening, a summary that clarifies. Interviewing is a craft. It has real skill in it. And the skill has always worked because a person with good judgment was moderating the process.
So what happens when you hand that skill over completely to something that isn’t a person at all? Nielsen Norman Group went and tested that idea with two AI-interviewer tools currently available for use, Marvin and UserFlix, in front of ten real participants. It’s not hypothetical anymore.
Let’s start with the one that surprised me the most. Summing up what people said, in their own words, was the single biggest thing that made them feel heard more than anything else the AI did. It’s a real technique, called mirroring, and it’s usually thought of as one of the harder, more human parts of interviewing. The machine, however, was good at the thing we’d might assume it would be worse at— making someone feel heard.
Utilizing that technique didn’t come without issues. Neither tool gave people a chance to confirm the summary was right before moving on. One participant said she interrupted the AI just to correct it, because she expected a pause and didn’t get one. In my opinion, that doesn’t look like a capability ceiling to me. AI is perfectly capable of asking: “Did I get that right, or is there more?” That looks an awful lot like a prompting omission than a limitation.
The pacing of the interviews also seemed to be an issue. The Interviews ran anywhere from 13 to 56 minutes because, according to NN/g, the AI couldn’t tell when a question had been covered enough to move on. NN/g claimed that a person discerns that from tone and body language. However, the AI doesn’t need to read tone and body language to navigate the issue. Give it an explicit list of objectives, let it track what’s covered, and have it probe a thread only while the objective stays unmet. And, yes, a non-answer is data I get that — when someone dodges, stalls, or can’t put something into words, that gap is often worth discovering. But a standing question after each answer — “Did you have more to say, or should we move on?” — hands the pacing control over to the participant instead of asking the model to guess from cues it can’t see.
There’s also a technique I’d call gentle probing. When the AI detects a vague or closed answer, it rephrases once, from a different angle. If the participant deflects again, it accepts that, notes how they declined, and asks if they’d like to move on. Honoring a refusal is just good research ethics, and it belongs in the system prompt like everything else here.
This study also noted that the AI’s praise came off as fake, so over-the-top that people stopped trusting it. This has to be the easiest fix on the list — dial back the flattery in the system prompt.
AI self-disclosure addresses this in a cleaner way though. A “tell” only works if something’s hidden, so if a participant is told upfront they’re talking to an AI, the fake-warmth problem may dissolve on its own — you can’t get caught pretending to be human if you never pretended. You can go further by framing the relationship from the start encouraging the participant to treat the AI as a thinking partner.
That leads to another finding that doesn’t get resolved as cleanly as a prompting fix. A couple of participants held back. One wouldn’t say where she worked even though it’s on her LinkedIn profile. She just didn’t feel comfortable telling the AI. She said she didn’t know how it would use it and that with a person, someone is accountable for what happens to that information.
Part of that is fixable, and the study says so plainly. The AI interviews should start with a proper introduction. A word about how the recording would be used can put that discomfort at ease. One participant spelled out the fix herself: have the AI say it’s an AI, say who it’s working for, say the conversation is confidential. That’s mostly a prompt modification, same as the previous three concerns.
Underneath all of that sits a second problem that disclosure can state but never fully resolve and the same participant named it: with a person, someone is answerable for what she said; with the AI, she just didn’t know. A confidentiality line can promise her words will be handled well, but it can’t produce the human who’s actually on the hook. You can’t script accountability. The researcher behind the AI—the “man behind the curtain”—should take intentional steps to build rapport with the participant. One option might be a short recorded introduction before the AI takes over.
That’s the piece that can’t be reduced to a prompt fix. The previous solutions came as part of the AI. This didn’t, because it was never an AI issue to begin with. It’s the trust that someone on the other end can be held to account.
Structured vs Semi-structured interviews
NN/g draws a line between structured and semi-structured interviews. Their claim is that AI can replace humans on the structured kind, where you follow a script. The open discovery that happens with semi-structured interviews is harder, they say, because it requires adapting on the fly in ways AI can’t yet manage.
I’d hold that line looser. A lot of what looks like adapting isn’t the model deciding more — it’s just more structure. Confirmation checks, pacing handoffs, gentle probes: these hand control to the participant rather than asking the model to judge anything. Much of what reads as “judgment” is really a question someone forgot to script, or a guardrail someone forgot to mention. Objective tracking, treating a non-answer as data, navigational control, honoring a refusal, dialing back the flattery — all addressable.
And the tools they tested were built for structured interviews in the first place, then judged for lacking the skills semi-structured work needs. That’s like benchmarking a Camry and concluding cars can’t go off-road. Most of what they flagged — no confirmation check, clumsy pacing, no way to revisit a question — are product gaps. The right kind a tool might be able to close them. Their claim that more autonomy would only make things worse isn’t a sure thing. It’s a snapshot of a single generation of models, written down as if it were a ceiling.
A fairer test needs a deeper agent: one that checks each answer for completeness, generates its own follow-ups, and keeps notes on the participant as the conversation builds. Run that on the most current frontier model and you’d be measuring what you claiming is out of reach, not the limits of two tools that were never built for it.
None of this is a knock on the study itself. If anything, it points to a need for more research on how modern AI actually performs in qualitative work, so practitioners have real guidance on when and how to use these tools. NN/g asked the right questions and ran it honestly, landing on advice I’d give clients myself: use AI for structured, well-scoped work that benefits from scale and consistency; and use it in collaboration with a human.
Today’s tools still struggle with the judgment semi-structured interviewing needs. But I think AI can get genuinely good at semi-structured interviews in the near future—especially if we define “good” as consistent, adaptive, nonjudgmental, and able to ask useful follow-up questions. Some day it may even be able to pick up on context that is currently blind to us.
